
本文介绍了数学中常用的希腊字母及其发音和应用。主要包括:α(阿尔法)用于表示角度、系数;β(贝塔)作为回归系数或角度辅助参数;γ(伽马)涉及伽马函数与热力学;Δ(德尔塔)代表差值,如变量增量;Σ(西格玛)是求和符号;μ(缪)指总体均值;小写σ(西格玛)表示标准差;χ²(卡方)用于卡方检验;ρ(柔)表示相关系数;λ(兰姆达)为泊松分布参数及特征值。这些符号在统计学、物理学等多个领域有广泛应用。
 Published on 2025-05-12
Published on 2025-05-12
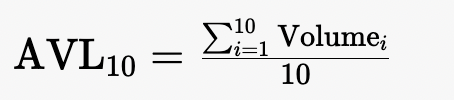 Published on 2025-03-17
Published on 2025-03-17
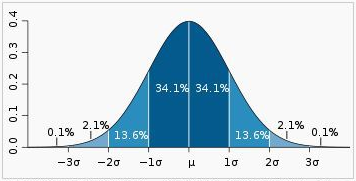
预训练技术(PTM)是一种通过大量未标记数据对模型进行训练的方法,以赋予模型先验知识和常识,从而提高其在各种任务上的表现。预训练主要解决数据稀缺性、先验知识需求、迁移学习问题以及模型可解释性等问题。预训练方法分为有监督预训练和自监督预训练两大类,前者常见于计算机视觉(CV)领域,后者则广泛应用于自然语言处理(NLP)中。在CV领域,从早期的AlexNet到最近的Swin Transformer等,预训练模型经历了从有监督向自监督的转变;而在NLP领域,自Word2Vec以来,GPT系列成为了当前最流行的预训练方式之一。此外,多模态预训练模型如DALL-E、CLIP等也展示了强大的跨模态理解能力。预训练不仅提高了模型性能,还促进了不同领域间的技术交流与融合。
Published on 2023-06-02
本文探讨了使用CPU和GPU进行模型训练的差异及优缺点。尽管CPU因计算单元少于GPU而不适合大规模并行运算,但依然可以用于模型训练。文章强调了GPU在深度学习中的优势,特别是在处理大规模数据集时。对于模型训练而言,适当的batch size至关重要,过小或过大都会影响训练效果。此外,介绍了单机多卡同步数据并行、模型并行以及流水线并行等技术来提高训练效率,并指出结合数据并行与模型并行能够实现更佳性能。最后,讨论了如何通过优化通信以实现模型并行、张量并行与数据并行的同时应用,从而达到最优训练效果。
Published on 2023-06-02
该文章介绍了三种重要的自平衡搜索树:AVL树、红黑树以及B树。AVL树是一种高度平衡的二叉搜索树,通过旋转操作保持左右子树的高度差不超过1,确保了查找、插入和删除操作的时间复杂度为O(log n)。红黑树也是一种自平衡二叉搜索树,但其平衡性要求较AVL树宽松,通过颜色标记节点来维护树的近似平衡状态,同样保证了高效的操作性能。而B树(或B-树)则是一种多路搜索树,特别适用于文件系统和数据库等场景下的数据存储与检索,能够有效地减少磁盘I/O操作次数。这三种树结构各有特点,在不同的应用场景下发挥着重要作用。
Published on 2023-05-12
本文介绍了对数函数log、lg和ln的区别及数学常数e的相关知识。对数函数中,lg是以10为底的对数,ln是以自然对数的底数e(约等于2.71828)为底的对数,而log则可以表示以任意正数为底的对数,具体底数通常会在符号下方注明。e是一个重要的无理数,在微积分、概率论等多个领域都有广泛应用。它最初由瑞士数学家欧拉在研究复利计算时提出,并且被定义为当n趋近于无穷大时(1+1/n)^n的极限值。此外,e还与自然对数有着密切联系。
Published on 2023-05-12