
预训练技术简介
https://www.yuque.com/meta95/hmc3l4/bbb88hai4hqi15ua?singleDoc# 《预训练技术简介》
定义
预训练(PTM)是一种机器学习技术,它使用大量未标记的数据对模型进行训练,以使其具备某些先验知识和常识,从而提高其在各种任务上的表现。
为什么需要预训练?
预训练技术被广泛应用于各种机器学习任务,主要是为了解决以下问题:
数据稀缺性:在许多任务中,标记数据是很昂贵的,并且难以获取。例如,在自然语言处理领域,需要大量的标注数据才能训练模型。通过使用预训练技术,可以利用未标记的数据来训练模型,从而提高模型的性能和泛化能力。
先验知识问题:许多机器学习任务需要模型具备一定的先验知识和常识,例如自然语言处理中的语言结构和规则。通过使用预训练技术,可以让模型在未标记数据上学习这些知识,从而使其在各种任务上表现更好。
迁移学习问题:许多机器学习任务之间存在共性,例如自然语言处理中的语义理解和文本分类等。通过使用预训练技术,可以将模型从一个任务迁移到另一个任务,从而提高模型在新任务上的性能。
模型可解释性问题:预训练技术可以帮助模型学习抽象的特征,从而提高模型的可解释性。例如,在自然语言处理中,预训练技术可以使模型学习单词和短语的表示,从而提高模型的可解释性。
总之,预训练技术可以帮助机器学习模型解决数据稀缺性、先验知识和迁移学习等问题,从而提高模型的性能和可解释性,同时降低训练成本。
预训练方法
预训练的核心思想是通过在大规模数据上进行训练,让模型学习到通用的特征和知识,从而提高其泛化能力和适应性。预训练方法通常包括两个步骤:
预训练(有监督/自监督):使用海量数据集来预训练模型,让模型学习到数据中的通用特征和结构。常用的预训练方法有自编码器、变分自编码器、对比学习等。
微调:在特定的任务上,使用有标注数据对预训练的模型进行微调,使其适应特定任务的需求。微调的过程通常包括在预训练模型的顶部添加一个新的输出层,然后使用有标注数据对整个模型进行 fine-tuning。
预训练的核心思想是让模型学习到数据中的通用特征和结构,从而提高其泛化能力和适应性。通过预训练,模型可以更好地处理新数据,同时减少对有标注数据的依赖,从而提高模型的效率和效果。预训练方法已经在自然语言处理、计算机视觉、语音识别等领域中得到了广泛应用,并取得了很多令人瞩目的成果。
按照是否有监督信息来分,预训练方式大致可以分为有监督预训练和自监督预训练。其中CV领域经历了从有监督预训练逐渐到自监督预训练的过渡,而NLP领域则一直采用的是自监督的预训练方式,只是经历了从Word2Vec到现在如日中天的GPT的演变过程。
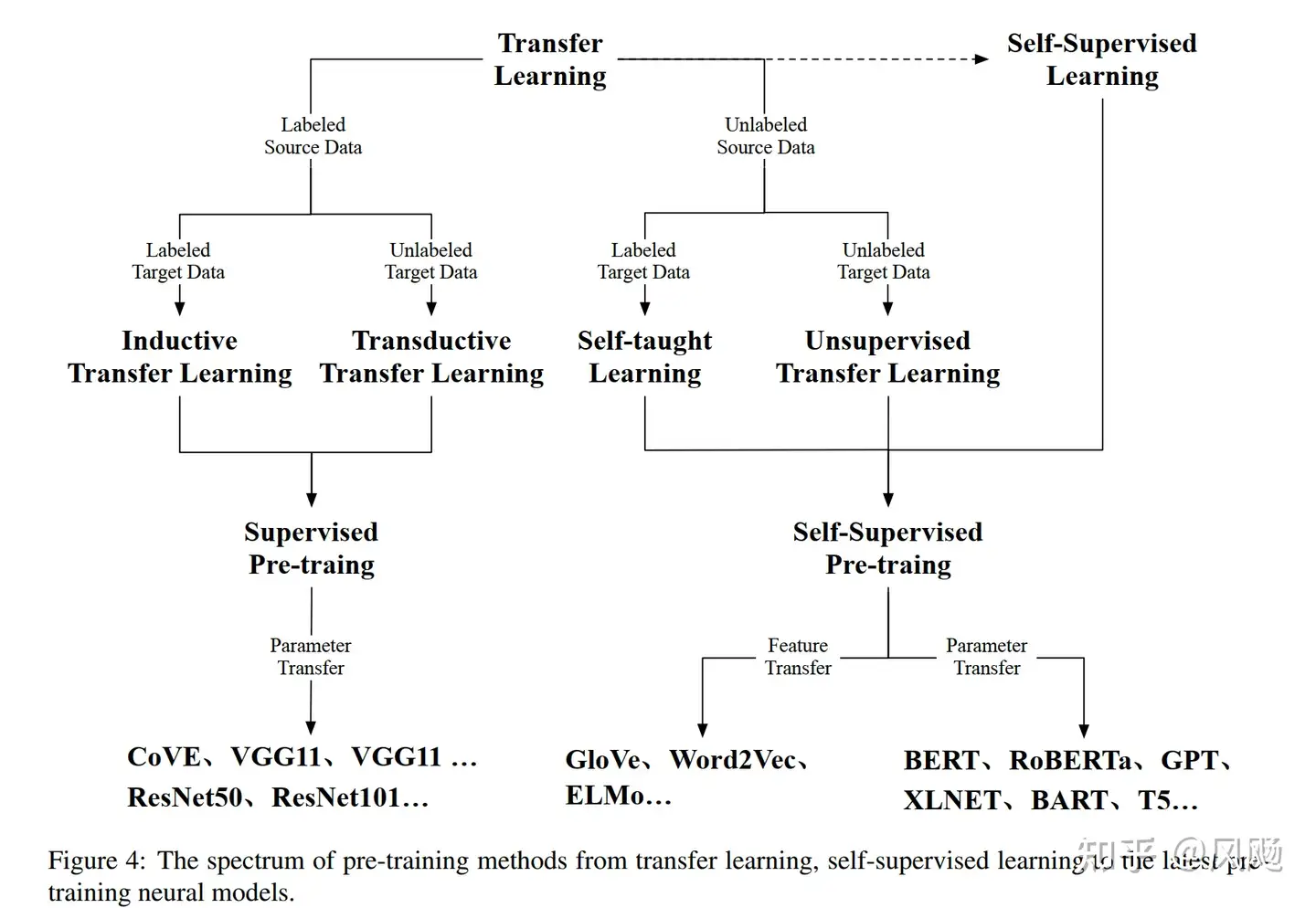
有监督预训练
主要运用在CV领域,典型的代表如下表
预训练模型 | 时间 | 方法简介 | 论文链接 |
AlexNet | 2012 | 通过深度卷积神经网络进行图像分类 | Link |
VGG | 2014 | 基于多层卷积网络的图像分类 | Link |
GoogLeNet | 2014 | Inception模块优化,使用平行卷积来提高网络深度和宽度 | Link |
ResNet | 2015 | 通过残差连接解决了深度网络中的梯度消失问题,提出了Residual Block | Link |
NASNet | 2018 | 使用神经结构搜索来设计神经网络结构,采用NAS算法进行网络自动设计 | Link |
EfficientNet | 2019 | 通过网络缩放系数、深度系数、宽度系数来构建一系列高效的模型 | Link |
自监督预训练
主要可以分为生成式(generative)和对比式两种。
CV领域
方法 | 时间 | 方法简介 | 生成式/对比式 | 论文链接 |
SimCLR | 2020 | 基于对比学习的自监督预训练模型,通过最大化同一图像的不同视角的相似性来学习表征 | 对比式 | Link |
MoCo | 2020 | 基于对比学习的自监督预训练模型,通过维护一个动态的字典来增强模型的表征能力 | 对比式 | Link |
SwAV | 2021 | 基于对比学习的自监督预训练模型,通过最大化不同图像的相似性来学习表征,并利用聚类方法进一步提高性能 | 对比式 | Link |
DINO | 2021 | 基于对比学习的自监督预训练模型,通过对齐不同尺度的特征来提高模型的表征能力 | 对比式 | Link |
Vision Transformer (ViT) | 2020 | 基于Transformer的视觉预训练模型,将输入图像分割成小的图块,然后将这些图块扁平化并馈送给Transformer模型进行预测。 | 生成式 | An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale |
DeiT | 2021 | 基于ViT的改进,使用更多的数据和更多的训练技巧进行训练,取得了更好的结果。 | 生成式 | Training data-efficient image transformers & distillation through attention |
PVT | 2021 | 基于ViT的改进,采用金字塔结构的注意力机制来处理不同尺度的特征,同时使用跨特征的注意力机制来捕获全局上下文信息。 | 生成式 | Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions |
Swin Transformer | 2021 | 基于ViT的改进,采用分层式的Transformer架构,从而使得模型可以处理更大的图像。 | 生成式 | Swin Transformer: Hierarchical Vision Transformer using Shifted Windows |
MAE | 2021 | 基于Masked Autoencoder的自监督预训练 | 生成式 | Link |
NLP领域
方法 | 时间 | 方法简介 | 生成式/对比式 | 论文链接 |
Word2Vec | 2013 | 通过从大规模文本语料中学习单词的分布式表示来进行预训练 | 生成式 | Efficient Estimation of Word Representations in Vector Space |
GloVe | 2014 | 通过从语料库中构建共现矩阵,再进行矩阵分解来获得单词向量 | 对比式 | GloVe: Global Vectors for Word Representation |
ELMo | 2018 | 基于双向语言模型,将单词的向量表示拆分成多个层次,将不同层次的表示组合在一起来获得更好的表示 | 生成式 | Deep contextualized word representations |
BERT | 2018 | 基于Transformer的预训练模型,通过掩盖输入中的单词来进行自监督学习 | 对比式 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding |
GPT | 2018 | 基于Transformer的自回归语言模型,通过最大化下一个单词的概率来进行预训练 | 生成式 | Improving Language Understanding by Generative Pre-Training |
XLNet | 2019 | 基于Transformer和自回归语言模型,使用permutation语言建模来进行预训练 | 生成式 | XLNet: Generalized Autoregressive Pretraining for Language Understanding |
RoBERTa | 2019 | 基于BERT的预训练模型,使用更多的训练数据和更长的训练时间来得到更好的效果 | 对比式 | RoBERTa: A Robustly Optimized BERT Pretraining Approach |
T5 | 2020 | 基于Transformer的预训练模型,将多个NLP任务转化为类似机器翻译的形式进行训练 | 生成式 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer |
GShard | 2021 | 使用分布式计算进行预训练,可以跨多个GPU和多个机器 | 对比式 | Scaling Up Fine-grained Pretraining for Natural Language Processing |
Speech领域
方法 | 时间 | 方法简介 | 生成式/对比式 | 论文链接 |
wav2vec | 2019 | 基于自编码器和对比学习的预训练模型,用于语音信号的特征学习 | 对比式 | |
wav2vec 2.0 | 2020 | 基于 wav2vec 的改进版,采用了掩码卷积和无监督掩码语言建模 | 对比式 | |
SimCLR-Voice | 2021 | 基于 SimCLR 的语音特征学习模型,使用对比学习框架 | 对比式 | |
CPC | 2019 | 基于预测下一个样本的对比学习的预训练模型,用于语音信号的特征学习 | 生成式 | |
VQ-Wav2Vec | 2020 | 基于向量量化技术和对比学习的预训练模型,用于语音信号的特征学习 | 对比式 | |
HuBERT | 2021 | 基于掩码语言建模和自编码器的预训练模型,用于语音信号的特征学习 | 生成式 | |
SpeechFormer | 2021 | 基于Transformer的语音自监督预训练模型,用于语音识别任务 | 生成式 |
多模态
模型 | 模态 | 时间 | 简介 | 生成式/对比式 | 论文链接 |
DALL-E | 图像、文本 | 2021 | 利用GAN框架进行训练,使得模型可以根据文本生成对应的图像 | 生成式 | Link |
UNITER | 图像、文本 | 2019 | 在Transformer的基础上,使用对比式学习方法进行训练,以建立图像和文本之间的联系 | 对比式 | Link |
CLIP | 图像、文本 | 2021 | 使用对比式学习方法,训练一个多模态的模型,能够根据文本或图像进行分类 | 对比式 | Link |
MoCoGAN | 图像、视频 | 2018 | 利用生成式对抗网络(GAN)框架,将视频的不同时间帧看作不同的图像进行训练,以学习视频生成的表示 | 生成式 | Link |
Act2Vec | 视频、动作 | 2018 | 利用对比式学习方法,将视频和动作编码到一个向量空间中,使得视频和动作之间可以进行比较 | 对比式 | Link |
VATEX-BERT | 视频、文本 | 2021 | 在BERT的基础上,使用对比式学习方法训练,建立视频和文本之间的联系 | 对比式 | Link |
参考
Han, Xu, et al. "Pre-trained models: Past, present and future." AI Open 2 (2021): 225-250.
https://zhuanlan.zhihu.com/p/459950752 预训练中的自监督学习
https://zhuanlan.zhihu.com/p/49271699 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
https://zhuanlan.zhihu.com/p/254821426乘风破浪的PTM:两年来预训练模型的技术进展
https://zhuanlan.zhihu.com/p/597586623 通向AGI之路:大型语言模型(LLM)技术精要
https://zhuanlan.zhihu.com/p/348593638 Vision Transformer , 通用 Vision Backbone 超详细解读 (原理分析+代码解读) (目录)
https://zhuanlan.zhihu.com/p/367290573 对比学习(Contrastive Learning):研究进展精要
https://zhuanlan.zhihu.com/p/435472828 Self-Supervised Learning 超详细解读 (七):大规模预训练 Image BERT 模型:iBOT